Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124

O Gemini Omni Flash é o modelo multimodal da Google capaz de criar e editar vídeos usando texto, imagem, áudio e vídeo como entrada simultaneamente.
O sistema combina raciocínio avançado do Gemini com geração audiovisual baseada em linguagem natural — aproximando software criativo de uma interface totalmente conversacional.
Em vez de operar timelines e menus, você simplesmente descreve o que quer.
Existe um padrão que qualquer editor de vídeo reconhece imediatamente: timeline na parte inferior da tela, camadas empilhadas, ferramentas na barra lateral, menus com dezenas de opções agrupadas por função. O Adobe Premiere usa esse modelo. O Final Cut também. O DaVinci Resolve também. Não porque é o melhor modelo possível — mas porque foi o que funcionou durante as últimas três décadas.
A interface de linha de tempo foi a melhor resposta que o setor encontrou para o problema de “como mostrar tempo e composição de forma compreensível para humanos”.
O Gemini Omni Flash sugere que essa pode não ser mais a única resposta.
A proposta da Google não é apenas criar mais uma ferramenta de geração de vídeo com IA. É testar se o software criativo pode ser operado por linguagem natural — onde você descreve o que quer em vez de arrastar keyframes e ajustar curvas de bezier.
Isso não é melhoria incremental. É mudança de paradigma.
💬 A tese central: O futuro do software criativo talvez não seja menus mais inteligentes. Talvez seja não ter menus.
Essa mudança de paradigma faz parte de uma transformação mais ampla que analisamos ao documentar como a mentalidade AI-first está redefinindo software e empresas →: quando a IA passa de assistente para interface principal, o que muda não é apenas a ferramenta — é o modelo mental de como o trabalho acontece.

O Gemini Omni Flash é um modelo multimodal — o que significa que ele não apenas processa um tipo de entrada, mas combina texto, imagem, áudio e vídeo simultaneamente para gerar e editar conteúdo audiovisual.
Isso parece técnico até você entender o que significa na prática.
Em modelos anteriores de IA para vídeo, você tipicamente escolhia um tipo de entrada — um texto descritivo, ou uma imagem de referência, ou um prompt de estilo — e recebia um vídeo como output. O processo era essencialmente unidirecional: você descreve, a IA gera, você avalia.
O Gemini Omni Flash trabalha de forma diferente. Ele pode receber simultaneamente uma imagem de referência visual, uma descrição textual do que deve acontecer, um áudio que vai guiar o ritmo ou o clima, e um vídeo existente que serve como base de edição — e sintetizar tudo isso em uma saída coerente.
Os exemplos que a Google demonstrou são reveladores. Uma escultura de argila que se transforma em objetos semelhantes mantendo a consistência visual do material. Um espelho líquido que reflete o ambiente de formas fisicamente plausíveis. Uma animação estilo claymation explicando conceitos científicos com precisão visual. O que todos esses exemplos têm em comum: consistência interna ao longo do tempo e coerência entre os diferentes elementos da cena — que historicamente são os dois problemas mais difíceis de IA de vídeo.
🔹 O que o Gemini Omni Flash faz que outros modelos ainda não fazem consistentemente:

Por décadas, o modelo de software criativo foi este: você aprende a ferramenta, e a ferramenta executa o que você sabe pedir a ela. A sofisticação do output era diretamente proporcional ao domínio técnico do operador.
O Gemini Omni não inverte completamente essa equação — mas desloca significativamente onde o domínio técnico é necessário. Em vez de precisar saber onde está o controle de temperatura de cor no After Effects, você descreve o efeito visual que quer. Em vez de montar uma composição layer by layer, você itera conversacionalmente até chegar no resultado desejado.
O fluxo muda assim:
Antes: Você abre o software → Aprende a interface → Monta manualmente cada elemento → Exporta.
Com Gemini Omni: Você descreve o que quer → IA gera uma versão → Você refina por conversa → IA ajusta → Você aprova ou pede nova iteração.
A diferença não é apenas de velocidade. É de quem pode criar. Um diretor criativo com visão forte mas sem habilidade técnica de edição passa a conseguir materializar ideias sem depender de um editor técnico para executar. Um creator solo consegue produzir output de qualidade de produção sem equipe.
💬 O que isso muda de verdade: Até agora, software criativo avançado amplificava quem já tinha habilidade técnica. A IA conversacional começa a amplificar quem tem visão criativa — independente de técnica. Essa diferença é maior do que parece.
Isso faz parte do mesmo movimento que documentamos ao analisar como o fim dos aplicativos tradicionais está acontecendo através de agentes de IA →: quando a interface vira linguagem natural, a barreira de acesso a ferramentas poderosas colapsa — e o que passa a importar é o que você tem a dizer, não o quanto você domina a ferramenta para dizê-lo.

O Gemini Omni Flash não surgiu no vácuo. Ele representa a próxima rodada de uma corrida que está definindo quem vai controlar a infraestrutura criativa da próxima década.
Durante anos, a evolução da IA seguiu um caminho relativamente linear: modelos de linguagem ficaram maiores, mais precisos, mais capazes. O GPT-3 virou GPT-4. O Gemini evoluiu. O Claude avançou. A competição era essencialmente textual.
Depois veio a imagem. Depois o código. Depois a voz. E agora, com força total, o vídeo.
A Google está apostando em multimodalidade como diferencial estratégico — usando a combinação de Gemini (raciocínio), Veo (geração de vídeo) e Google Flow (produção cinematográfica assistida por IA) para criar um ecossistema criativo integrado. O Gemini Omni é a camada que conecta tudo isso em uma interface conversacional.
A OpenAI tem o Sora, que demonstrou capacidades impressionantes de geração de vídeo com qualidade cinematográfica. A integração com o ecossistema GPT cria uma proposta similar — mas com foco maior em geração de alta qualidade do que em edição iterativa conversacional.
A Meta está investindo pesado em Movie Gen e modelos multimodais abertos, com uma aposta em democratização através de modelos open source que podem ser rodados por desenvolvedores independentes.
A Anthropic permanece focada em linguagem e raciocínio — mas a pressão do mercado vai eventualmente empurrar para capacidades multimodais mais amplas.
Como analisamos ao documentar o que são agentes de IA e como eles estão transformando o software →, a evolução não é linear — é em camadas. LLMs viram copilotos, copilotos viram agentes, agentes estão virando sistemas multimodais completos que operam em múltiplos domínios simultaneamente.

A parte técnica mais interessante do Gemini Omni Flash não é a qualidade visual dos frames individuais — é a coerência ao longo do tempo.
Gerar uma imagem bonita com IA é um problema razoavelmente resolvido. Gerar 24 imagens bonitas por segundo, onde cada uma é fisicamente consistente com a anterior, onde personagens mantêm sua aparência, onde a física do ambiente faz sentido e onde a narrativa visual progride de forma coerente — esse é o problema difícil.
O Gemini Omni ataca esse problema usando o que a Google chama de raciocínio temporal: o modelo não apenas gera cada frame, mas “entende” o que aconteceu antes e o que deveria acontecer depois dentro da lógica da cena.
Na prática, isso se manifesta em capacidades como:
Consistência de material: uma cena com argila mantém as propriedades visuais e físicas da argila ao longo de toda a sequência — quando o material deforma, defoma de forma plausível para argila.
Física de referência cruzada: quando você fornece uma imagem de referência com um espelho e pede uma animação com reflexo líquido, o modelo usa a referência para calibrar como a luz e o reflexo deveriam se comportar no contexto específico daquela cena.
Edição iterativa com memória contextual: quando você pede para ajustar um elemento — “torna o movimento mais lento na parte do meio” — o modelo aplica o ajuste mantendo coerência com o resto do vídeo, sem precisar regerar tudo do zero.
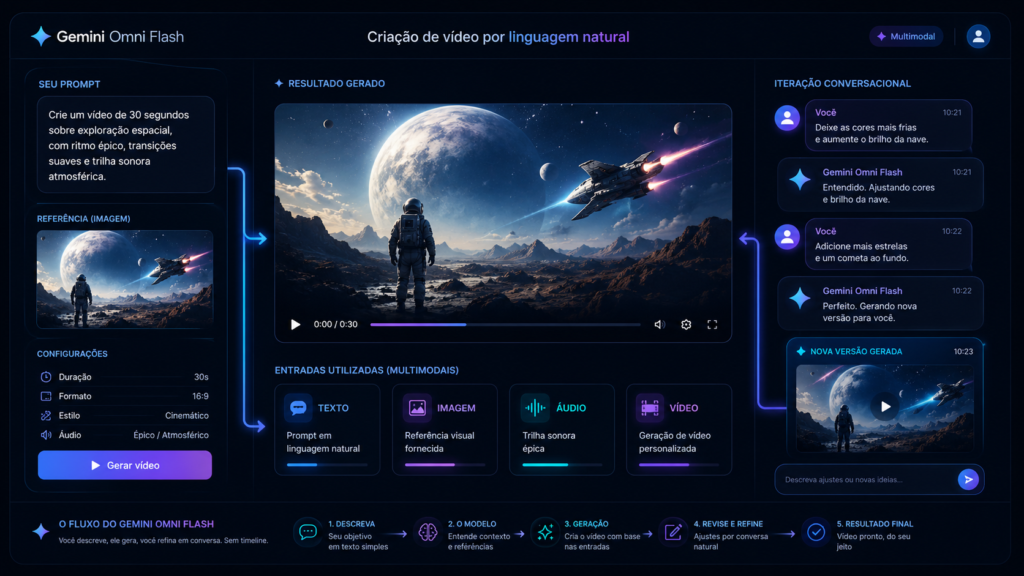
O impacto do Gemini Omni Flash para criadores de conteúdo não está apenas em “gerar vídeos mais rápido”. Está em mudar quem pode criar o quê — e com que estrutura de custo.
Para creators independentes: a barreira entre ter uma ideia visual e conseguir materializar essa ideia com qualidade profissional colapsa. Um criador com visão forte mas sem habilidade técnica de edição passa a conseguir produzir conteúdo que antes exigiria uma equipe de produção. Isso não elimina editores profissionais — mas muda radicalmente a relação de dependência.
Para agências pequenas: o custo de produção audiovisual cai em ordens de magnitude para determinados tipos de conteúdo. Animações explicativas, vídeos de produto, conteúdo para redes sociais — categorias que antes exigiam dias de trabalho começam a ser produzidas em horas. Isso não elimina o trabalho criativo, mas libera capacidade para mais clientes e mais iteração.
Para equipes de produto: demonstrações de produto, tutoriais, onboarding em vídeo — conteúdos que ficavam na fila de backlog por semanas por custo de produção passam a ser possíveis sem orçamento dedicado.
O gargalo que emerge — e que é importante nomear — é o mesmo que vimos em outras adoções de IA em escala. Quando a produção acelera, a coordenação vira o novo limitante. Como mostramos ao analisar como profissionais aumentados pela IA estão reorganizando o trabalho →: mais output gerado significa mais pontos de aprovação, mais decisões editoriais, mais distribuição para gerenciar. A IA acelerou a execução — a coordenação ainda é humana.
E para operações solo, esse padrão se manifesta de forma específica. Como documentamos ao analisar como a empresa de uma pessoa só está se tornando realidade operacional →, a IA expande dramaticamente o que um criador individual consegue produzir — mas exige que esse criador também assuma funções de direção criativa, aprovação editorial e distribuição que antes eram papéis diferentes.
A comparação honesta entre as plataformas de IA de vídeo disponíveis hoje revela que elas não competem exatamente no mesmo espaço — o que importa mais do que qual tem melhor “nota geral”.
| Gemini Omni Flash | Sora (OpenAI) | Runway Gen-3 | Veo (Google) | |
|---|---|---|---|---|
| Multimodalidade | ✅ Texto + imagem + áudio + vídeo | ⚠️ Principalmente texto e imagem | ⚠️ Texto e imagem | ✅ Alta |
| Edição iterativa | ✅ Conversacional nativo | ⚠️ Limitada | ✅ Boa | ⚠️ Em desenvolvimento |
| Consistência temporal | ✅ Forte | ✅ Forte | ⚠️ Variável | ✅ Forte |
| Integração de ecossistema | ✅ Google Workspace, YouTube | ✅ GPT-4, DALL-E | ⚠️ Standalone | ✅ Google Flow |
| API disponível | ⚠️ Em expansão | ⚠️ Limitada | ✅ Disponível | ⚠️ Em expansão |
| Qualidade cinematográfica | ✅ Alta | ✅ Alta | ✅ Boa | ✅ Alta |
| Foco principal | Interface conversacional | Geração de alta qualidade | Workflow de produção | Produção cinematográfica |
| Melhor para | Edição iterativa, creators | Geração do zero, qualidade | Produção recorrente | Projetos longos, cinema |
O Runway tem a vantagem de ter API mais matura e workflow estabelecido para produção recorrente. O Sora impressiona em qualidade de output para geração do zero. O Gemini Omni se diferencia pela interface conversacional e pela integração multimodal — que, se funcionar como demonstrado, representa um salto real em usabilidade.
O que vai definir qual plataforma domina não é a qualidade técnica isolada — é quem vai integrar melhor ao fluxo real de trabalho de criadores e equipes. E nessa dimensão, a integração com Google Workspace, YouTube Studio e Google Flow dá ao Gemini Omni uma vantagem estrutural que os concorrentes vão ter dificuldade para replicar.

O Gemini Omni Flash é impressionante. E exatamente por isso, levanta questões que não podem ser ignoradas.
Quando uma ferramenta consegue gerar vídeos realistas a partir de texto e imagens de referência, a linha entre “conteúdo criado” e “conteúdo falsificado” fica genuinamente difícil de distinguir. Deepfakes — vídeos manipulados que colocam o rosto ou a voz de pessoas reais em situações que nunca aconteceram — já eram um problema antes da IA generativa de vídeo. Com ferramentas como o Gemini Omni, a capacidade técnica necessária para criar esse tipo de conteúdo cai para zero.
A Google está implementando o SynthID — um sistema de watermark invisível que embute metadados no próprio vídeo gerado, de forma que detectores possam identificar que o conteúdo foi gerado por IA mesmo que o vídeo seja editado ou comprimido. É um mecanismo técnico real — mas com limitações reais também. SynthID funciona para conteúdo gerado dentro do ecossistema Google. Não funciona para conteúdo gerado em plataformas que não implementam o padrão.
O debate sobre autenticidade digital deve crescer nos próximos anos de forma proporcional à capacidade das ferramentas. Regulação está emergindo em alguns mercados — a União Europeia está avançando em requisitos de transparência para conteúdo gerado por IA — mas ainda com defasagem significativa em relação à velocidade de desenvolvimento técnico.
Para criadores profissionais, isso tem uma implicação prática imediata: a proveniência do conteúdo vai se tornar um diferencial de credibilidade. Quem pode demonstrar que seu conteúdo foi criado por humanos — ou que IA foi usada de forma transparente e documentada — vai ter vantagem de confiança em mercados onde isso importa.
IA de vídeo resolve o problema de ‘como criar’.
O próximo problema que cria é ‘como provar que é real’. E esse segundo problema é muito mais difícil.
Se o Gemini Omni Flash representa uma direção real — e há razões sólidas para acreditar que representa —, o software criativo dos próximos cinco anos vai parecer muito diferente do que usamos hoje.
O modelo que está emergindo não é “Premiere com IA embutida” ou “After Effects com botão de gerar”. É algo mais próximo de um sistema onde você expressa intenção criativa em linguagem natural, e o sistema orquestra múltiplas ferramentas especializadas para materializar essa intenção.
Isso muda profundamente o que significa ser editor de vídeo. Não da forma apocalíptica que parte do debate público sugere — editores não vão desaparecer amanhã. Mas o perfil de habilidades que vai ser mais valorizado muda: de domínio técnico de ferramentas específicas para direção criativa, julgamento editorial e capacidade de supervisionar sistemas que executam tecnicamente.
É o mesmo padrão que observamos em outras áreas de trabalho com IA. Como analisamos ao documentar como as novas profissões criadas pela IA estão se formando →: as funções mais valorizadas não são as que programam a IA, mas as que sabem o que pedir para ela e quando o resultado está certo.
Para quem está construindo operações criativas com IA hoje, o artigo sobre como workflows com IA criam alavancagem operacional → cobre a arquitetura de como integrar ferramentas como o Gemini Omni a fluxos completos de produção — da ideia ao produto final publicado.
A Google não lançou apenas mais uma ferramenta de geração de vídeo. Lançou uma declaração sobre onde o software criativo está indo — e sobre quem quer estar no centro disso quando o mercado chegar lá.
A aposta é clara: a próxima geração de software criativo será operada por linguagem natural multimodal, não por timelines e menus. E quem construir a melhor interface para isso — com o melhor ecossistema de integração, com as melhores capacidades de consistência e iteração — vai capturar o mercado de criação audiovisual da mesma forma que Google Docs capturou o mercado de documentos.
Ainda existem limitações reais. A consistência perfeita ainda falha em casos complexos. A integração com fluxos profissionais estabelecidos ainda está se formando. E as questões sobre autenticidade e deepfakes ainda não têm resposta técnica completa.
Mas a direção está estabelecida. E quem aprender a trabalhar com esse modelo de criação agora vai ter uma vantagem que vai ser difícil de alcançar depois — quando todo mundo já estiver usando.
O Gemini Omni Flash mostra que o futuro do software criativo talvez não seja editar mais rápido.
Seja não precisar mais editar.
E quando isso se tornar realidade, o que vai valer não é mais o domínio da ferramenta.
É o que você tem para dizer — e a clareza para dizer.
📩 Toda semana, o SPTechBR analisa o que está realmente mudando com IA — no software criativo, no trabalho e no mercado. Sem hype e sem ignorar o que ainda não funciona.
💻 CMD em 2026: por que a linha de comando ainda é uma vantagem competitiva — e os comandos que realmente importam
A IA aumentou o valor de quem sabe controlar sistemas diretamente. O terminal continua sendo uma camada estratégica para produtividade, automação e infraestrutura.
🧠 Plano da OpenAI para IA: como Sam Altman quer redefinir economia, trabalho e poder
O projeto da OpenAI vai muito além de chatbots — e pode remodelar infraestrutura digital, mercado de trabalho e concentração de poder tecnológico.
⚡ Como rodar IA local em 2026: guia prático com Ollama, LM Studio e os melhores modelos open source
Modelos locais estão transformando privacidade, custo operacional e autonomia em inteligência artificial — sem depender totalmente da nuvem.
O Gemini Omni Flash é o modelo multimodal da Google que combina texto, imagem, áudio e vídeo como entradas simultâneas para criar e editar vídeos usando linguagem natural. Ele representa a aposta da Google de que o futuro do software criativo será operado por conversa, não por timelines e menus.
São concorrentes no mercado de IA de vídeo, mas com propostas distintas. O Sora da OpenAI foca em geração de alta qualidade cinematográfica a partir de texto. O Gemini Omni se diferencia pela multimodalidade combinada e pela edição iterativa conversacional — onde você refina o resultado em conversa em vez de regerar do zero.
Sim — essa é uma das capacidades mais relevantes. Você pode fornecer um vídeo existente como entrada e pedir modificações específicas em linguagem natural. O modelo aplica as mudanças mantendo coerência com o restante do conteúdo, sem precisar recomeçar a geração.
IA multimodal refere-se a modelos que processam e combinam múltiplos tipos de entrada — texto, imagem, áudio, vídeo — simultaneamente. Em vez de ser especializado em um tipo de dado, o modelo entende as relações entre diferentes mídias e pode gerar output que integra todas elas de forma coerente.
Para criação de vídeos explicativos, animações de produto, conteúdo para redes sociais e edição iterativa de material existente. O fluxo principal é: você descreve o que quer + fornece referências visuais ou de áudio → o modelo gera uma versão → você refina em conversa até chegar no resultado desejado.
A Google está expandindo gradualmente o acesso via API dentro do ecossistema Google Cloud e AI Studio. Para projetos que precisam de integração em workflows de produção, acompanhe os releases do Google DeepMind — o acesso tende a se expandir conforme o modelo matura em produção.