Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


Por que o modelo mais aguardado de 2026 ainda não chegou — e o que isso revela sobre a maior aposta tecnológica da China
📩 Quer dominar IA, automação e as ferramentas que estão mudando o mercado?
Assine a newsletter do SPTechBR e receba análises práticas e diretas toda semana 🚀
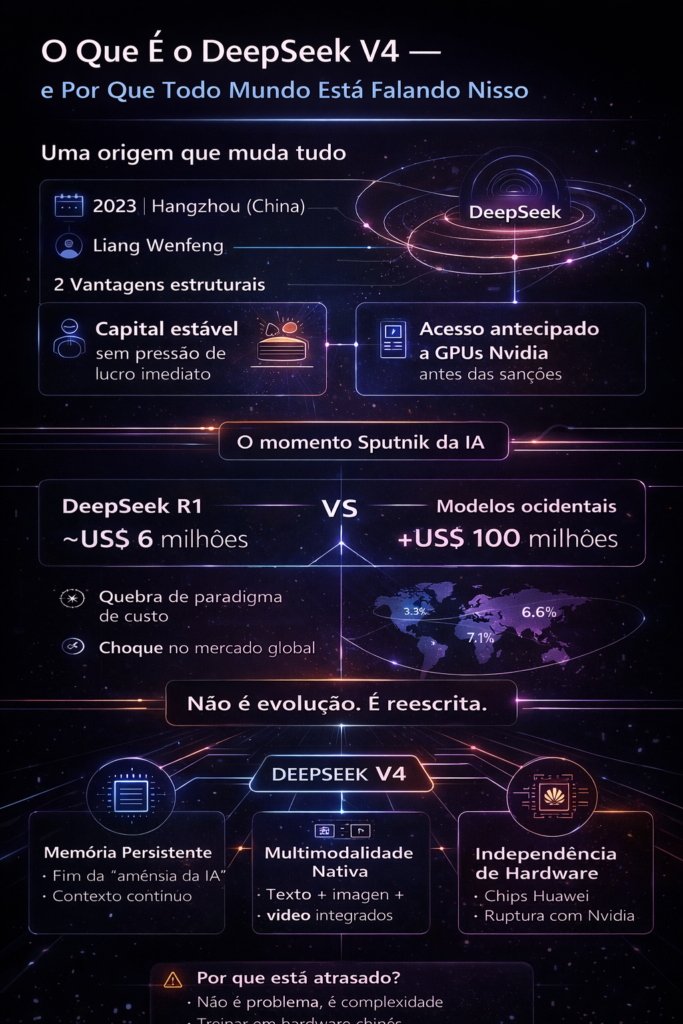
Desde que o DeepSeek R1 sacudiu o mercado global de inteligência artificial em janeiro de 2025 — derrubando US$ 600 bilhões em valor de mercado da Nvidia em um único pregão e forçando o mundo a repensar quem de fato lidera a corrida da IA —, nenhuma empresa concentrou tanta expectativa sobre um único lançamento quanto a startup de Hangzhou agora concentra no seu DeepSeek V4.
O problema é que ele simplesmente não veio. Nem em fevereiro, durante o Ano Novo Chinês. Nem em março, às vésperas das “Duas Sessões” parlamentares. Cada janela de lançamento passou em silêncio, enquanto a comunidade técnica global ficava debruçada sobre modelos misteriosos no OpenRouter, papéis acadêmicos assinados pelo próprio fundador Liang Wenfeng e sinais cifrados nos logs de atualização da API pública da empresa.
Para entender a magnitude do V4, é preciso entender de onde veio a DeepSeek. Fundada em 2023 por Liang Wenfeng em Hangzhou — a cidade que os chineses chamam de seu Vale do Silício —, a empresa nasceu como um projeto paralelo de um fundo de hedge de alta tecnologia. Essa origem incomum lhe deu duas vantagens que empresas de IA tradicionais raramente têm: fluxo de caixa estável sem pressão de lucratividade imediata e acesso antecipado a processadores Nvidia antes que as sanções americanas endurecedem os controles de exportação.
Quando o R1 foi lançado em janeiro de 2025 mostrando capacidade de raciocínio comparável ao OpenAI o1, mas treinado por uma fração do custo — estimativas apontam para cerca de US$ 6 milhões contra os mais de US$ 100 milhões gastos por rivais ocidentais —, o mercado entrou em colapso. A comparação com o Sputnik foi imediata e universal.
Desde então, a DeepSeek se consolidou como a 4ª maior aplicação de IA para web do mundo, segundo dados da venture capital a16z, sendo a empresa chinesa mais bem posicionada em um ranking dominado por nomes americanos. Sua base de usuários é estrategicamente distribuída: 33,5% na China, 7,1% na Rússia e 6,6% nos Estados Unidos — uma penetração que nenhum outro produto de IA conseguiu alcançar simultaneamente nos três grandes ecossistemas geopolíticos do planeta.
O DeepSeek V4 não é uma atualização de versão. É uma reescrita filosófica de como um modelo de IA deve funcionar. Segundo fontes reportadas pelo Financial Times, Reuters e múltiplos meios especializados em tecnologia chinesa, o modelo apresenta três inovações centrais que, se entregues como prometido, redefinirão os padrões do setor: memória persistente nativa, multimodalidade completa e independência de hardware ocidental.
O atraso, segundo analistas ouvidos pelo Financial Times, se explica justamente pela ambição dessas inovações — especialmente pelo desafio de treinar um modelo desse porte em chips da Huawei, cujo ecossistema de software ainda está amadurecendo.
Você já explicou um projeto inteiro para um assistente de IA e, no dia seguinte, teve que começar do zero porque ele não lembrava de nada? Esse comportamento tem um nome técnico: é uma limitação estrutural da arquitetura Transformer, que domina os grandes modelos de linguagem desde 2017.
Todos os modelos atuais — ChatGPT, Claude, Gemini, o próprio DeepSeek V3 — funcionam com o que os engenheiros chamam de “janela de contexto”. É como um caderno com páginas limitadas: a IA pode ler e escrever nessas páginas durante uma conversa, mas quando o caderno enche ou a sessão termina, tudo some. Para “lembrar” de algo, o modelo precisa escrever no caderno — e cada linha escrita custa dinheiro em tokens processados.
Para agentes de IA autônomos — os sistemas que deveriam executar tarefas complexas de forma independente, gerenciar finanças, organizar fluxos de trabalho ou conduzir pesquisas ao longo de dias — essa limitação é fatal. Um agente que esquece o que fez ontem não é um agente; é uma calculadora cara.
A resposta da DeepSeek chega na forma do Módulo Engram, descrito em um paper acadêmico publicado em 13 de janeiro de 2026 e co-assinado pelo próprio fundador Liang Wenfeng — um sinal raro de que a empresa considera essa tecnologia central o suficiente para colocar seu nome nela.
O nome é uma referência direta à neurociência: engrams são os traços físicos que memórias deixam no cérebro. Tecnicamente, o sistema implementa o que os pesquisadores chamam de “Conditional Memory via Scalable Lookup” — memória condicional por busca escalável. Em linguagem acessível: ao invés de forçar o modelo a processar tudo como informação nova a cada vez, o Engram separa conhecimento estático (coisas que nunca mudam, como “Nova York é uma cidade”) de raciocínio dinâmico (inferências e contextos ativos).
Pense na diferença entre um dicionário e uma conversa. Um Transformer tradicional consulta seu “dicionário interno” do mesmo jeito para responder “qual é a capital da França” e para resolver um problema de lógica complexo — todo o peso computacional é ativado igualmente. O Engram cria uma “memória compartilhada” entre os especialistas do modelo (em uma arquitetura de Mistura de Especialistas, ou MoE), permitindo que fragmentos de conhecimento sejam recuperados de forma muito mais eficiente.
Os números projetados são expressivos: decodificação de inferência 300% mais rápida em comparação com o V3 e manutenção de taxas de recuperação extremamente altas mesmo em documentos com mais de um milhão de tokens. Para efeito de comparação, um milhão de tokens equivale a aproximadamente 750 mil palavras — o tamanho de cerca de seis romances normais, ou o código-fonte completo de um projeto de software médio.
Para empresas, o impacto é direto: agentes que gerenciam processos de semanas sem “esquecer” etapas concluídas, assistentes jurídicos que retêm contexto de processos inteiros, sistemas financeiros que lembram de preferências e histórico de decisões sem precisar reprocessar todo o histórico a cada consulta.
Há um paradoxo fascinante no coração da história da DeepSeek: as mesmas sanções que deveriam limitar o avanço tecnológico chinês estão, na prática, forçando uma inovação que pode se tornar mais valiosa a longo prazo do que simplesmente ter acesso a chips mais potentes.
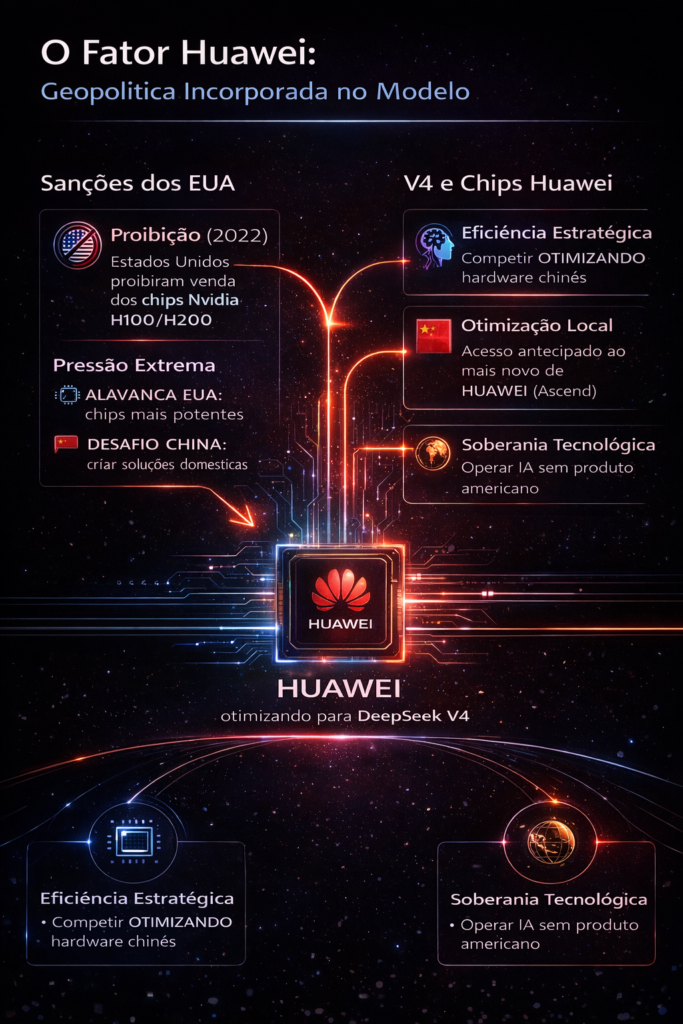
Desde 2022, os Estados Unidos proíbem a venda dos processadores mais avançados da Nvidia — especialmente os modelos H100 e H200 — para entidades chinesas. A lógica era simples: sem o hardware de ponta, as empresas de IA chinesas não conseguiriam treinar modelos de fronteira. O que aconteceu foi o oposto.
A DeepSeek demonstrou, já com o R1, que é possível criar modelos competitivos com hardware inferior se você otimizar radicalmente a arquitetura. Enquanto as empresas americanas continuam construindo modelos que exigem clusters de milhares de GPUs Nvidia de última geração, a DeepSeek desenvolveu técnicas que espremem muito mais eficiência de cada unidade computacional disponível.
O DeepSeek V4 eleva essa estratégia a um novo patamar. Segundo reportagem do Financial Times baseada em duas fontes com conhecimento direto do projeto, a empresa trabalhou ativamente com a Huawei e a Cambricon — os dois principais fabricantes de chips de IA da China — para otimizar o V4 para o hardware doméstico mais recente dessas empresas.
Também segundo o Financial Times, foi justamente esse processo que causou os atrasos no lançamento: as tentativas iniciais de treinar o modelo nos chips Ascend da Huawei encontraram problemas de estabilidade, velocidade de interconexão entre chips e imaturidade do ecossistema de software. A DeepSeek não desistiu. Investiu tempo e engenharia para resolver esses problemas — e as falhas de treinamento relatadas no início de 2026 foram, segundo analistas, parte do custo de criar algo que ninguém havia feito antes.
Reuters reportou em fevereiro de 2026 que a DeepSeek deu acesso antecipado ao V4 a fornecedores domésticos de chips, incluindo a Huawei, mas não ofereceu o mesmo à Nvidia ou à AMD. É um sinal inequívoco de alinhamento estratégico com o objetivo de soberania tecnológica declarado pelo governo chinês.
Se o V4 entregar o que promete rodando em hardware da Huawei, as implicações geopolíticas serão profundas: a China terá demonstrado que consegue operar na fronteira da IA sem depender de silício americano. As sanções dos EUA perdem uma de suas principais alavancas de pressão.
Com base em vazamentos técnicos e no histórico da série, o V4 deve continuar a arquitetura de Mistura de Especialistas (MoE) que tornou o V3 tão eficiente, mas em escala dramaticamente maior. Análises da comunidade técnica no Reddit e no X apontam para aproximadamente 1 trilhão de parâmetros totais — um salto significativo em relação ao V3, que opera com 671 bilhões de parâmetros no modo MoE.
O que diferencia o MoE do V4 é que a maioria dos parâmetros permanece inativa para qualquer consulta específica: apenas uma fração dos “especialistas” é acionada a cada vez, tornando o custo computacional real muito menor do que o número bruto de parâmetros sugere. Com as otimizações do Engram, a utilização de parâmetros deve melhorar em 40% em relação ao V3.
O V4 deve chegar com uma janela de contexto de 1 milhão de tokens, colocando-o na mesma classe que o Gemini 1.5 da Google. A diferença está na qualidade da recuperação: uma janela enorme com recuperação ruim é menos útil do que uma janela menor com recuperação excelente. O Engram foi projetado justamente para garantir que a capacidade de 1 milhão de tokens seja utilizada com alta fidelidade, não apenas como número de marketing.
O V4 representa uma quebra de paradigma na estratégia da DeepSeek. Modelos anteriores eram primariamente focados em texto. O V4 será, segundo o Financial Times e fontes técnicas, um modelo nativamente multimodal — capaz de processar e gerar texto, imagem e vídeo de forma integrada, não como módulos separados acoplados ao modelo principal.
Isso significa, na prática, que o V4 poderá ler uma tabela de um PDF e gerar automaticamente um script de análise em Python; transformar uma maquete de interface em código frontend funcional; ou interpretar um vídeo e produzir um resumo estruturado com timestaps — tudo dentro de um único modelo, sem orquestração entre sistemas separados.
Dois modelos anônimos que apareceram na plataforma OpenRouter — chamados pela comunidade de “Healer Alpha” e “Hunter Alpha” — foram amplamente especulados como versões de teste do V4. O “Healer Alpha” é descrito como um sistema de interação multimodal com 260 mil tokens de contexto e capacidade de percepção visual e auditiva; o “Hunter Alpha” se apresentou como um modelo de 1 trilhão de parâmetros com janela de 1 milhão de tokens projetado para fluxos de trabalho de agentes. No entanto, uma atualização de 18 de março de 2026 da Reuters confirmou que o “Hunter Alpha” era, na verdade, o MiMo-V2-Pro da Xiaomi — não o V4 da DeepSeek.
A codificação sempre foi o forte da série DeepSeek, e o V4 não abre mão dessa vantagem. Benchmarks internos não verificados por terceiros apontam para uma precisão de 83,7% no SWE-bench Verified — um dos testes mais exigentes de engenharia de software real, que avalia a capacidade do modelo de resolver issues reais de repositórios GitHub, com múltiplos arquivos e dependências complexas.
Para contextualizar: o Claude Opus 4.5, da Anthropic, atualmente lidera esse benchmark com cerca de 80,9%. Se os números do V4 se confirmarem em avaliações independentes, a DeepSeek assumiria a liderança na métrica mais valorizada pela comunidade de desenvolvedores.
É importante ser honesto sobre a incerteza aqui: esses são benchmarks internos, não verificados por terceiros. Até que avaliações independentes confirmem os resultados após o lançamento público, os números devem ser tratados como aspiracionais.

A DeepSeek já é conhecida no setor como a empresa que quebrou a estrutura de preços da IA. Enquanto o GPT-4 da OpenAI cobra cerca de US$ 30 por milhão de tokens processados, o DeepSeek opera na faixa de US$ 0,14 por milhão de tokens — uma diferença de mais de 200 vezes. O Claude da Anthropic, por sua vez, opera em torno de US$ 15 por milhão de tokens.
Essa assimetria de preços não é apenas uma estratégia comercial: é uma consequência direta da eficiência arquitetônica. Quando você precisa de menos poder computacional para obter o mesmo resultado, o custo cai. Com o V4 e as otimizações do Engram — que reduzem ainda mais o consumo computacional por consulta —, as projeções apontam para preços iguais ou inferiores ao nível atual do V3.
Para empresas que estão avaliando a viabilidade de agentes de IA autônomos, essa diferença de custo é a diferença entre um projeto economicamente inviável e um que pode ser escalado. Agentes que realizam centenas de consultas por hora, ao longo de semanas, são simplesmente proibitivos nas plataformas ocidentais para a maioria das pequenas e médias empresas.
A DeepSeek comprometeu-se a lançar o V4 sob licença aberta — provavelmente MIT ou Apache 2.0, seguindo o padrão das versões anteriores. Isso não é filantropia: é estratégia. Ao liberar os pesos completos do modelo, a empresa garante adoção massiva por desenvolvedores e empresas ao redor do mundo, especialmente em mercados emergentes sensíveis a custos.
A estratégia já funcionou: os modelos V3 e R1 foram amplamente adotados por laboratórios e empresas chinesas, que usaram as receitas de treinamento abertas para acelerar seus próprios desenvolvimentos. A DeepWisdom, por exemplo, quase fechou as portas antes do sucesso do ecossistema DeepSeek — e captou US$ 30 milhões em duas rodadas depois que o entusiasmo gerado pela empresa elevou o valuation médio de projetos de IA de US$ 10-20 milhões para US$ 20-40 milhões.
O cenário competitivo global da IA está se reorganizando em torno de três ecossistemas distintos. O ocidental é dominado por ChatGPT, Gemini, Claude e Perplexity. O russo está crescendo impulsionado por sanções, com o Yandex e o GigaChat capturando mercado local. E o chinês, liderado por DeepSeek, Doubao (ByteDance) e Kimi, está pela primeira vez ameaçando o domínio global.
Um dado que passou despercebido pela maioria dos portais ocidentais: dados de fevereiro de 2026 mostram que modelos chineses — incluindo DeepSeek, Alibaba e Zhipu — já representam 85% das chamadas de API globais, superando os EUA pela primeira vez na história da IA moderna. Esse número deve ser interpretado com cautela (inclui muitas chamadas de baixo custo e alto volume da própria China), mas é um sinal de que a massa crítica de adoção está mudando de endereço.
Seria desonesto ignorar os pontos de tensão na trajetória da DeepSeek. Dados recentes do SimilarWeb mostram que, apesar da posição de destaque no ranking global, o tráfego da DeepSeek sofreu uma retração de crescimento anual significativa, enquanto rivais como Gemini e Claude registraram expansão exponencial. O “choque do R1” criou expectativas altíssimas que são difíceis de sustentar.
A pergunta que a indústria está fazendo é legítima: a DeepSeek sabe reter usuários além do impacto inicial? A resposta dependerá muito do V4. Se o modelo entregar a experiência de memória persistente que promete, a dinâmica de retenção muda fundamentalmente — porque usuários que constroem um histórico de interação com um modelo ganham um custo de troca significativo.
Para quem está acompanhando a saga do V4, a sequência de datas é tão reveladora quanto os próprios anúncios técnicos.
Em 9 de janeiro de 2026, a Reuters reportou, citando o The Information, que a DeepSeek planejava lançar um novo modelo focado em codificação em fevereiro. Em 13 de janeiro, o paper do Engram foi publicado com a assinatura de Liang Wenfeng — confirmando indiretamente que algo grande estava sendo preparado. O Ano Novo Chinês, em 17 de fevereiro, passou sem anúncio. Em 27 de fevereiro, a Reuters reportou que a DeepSeek havia dado acesso antecipado ao V4 a fabricantes domésticos de chips, excluindo Nvidia e AMD — um sinal de que o modelo existia, mas não estava pronto para o público.
Em 9 de março, a mídia técnica chinesa reportou uma atualização no website da DeepSeek que parte da comunidade chamou de “V4 Lite” — mas a empresa nunca confirmou o nome ou as especificações. Em 11 de março, o “Hunter Alpha” apareceu no OpenRouter e acendeu especulações — até ser identificado como o MiMo-V2-Pro da Xiaomi em 18 de março. Em 23 de março, uma atualização do tracker de lançamento do Verdent confirmou: o V4 ainda não havia sido lançado publicamente, com múltiplas janelas tendo passado sem confirmação oficial.
Hoje, 28 de março de 2026, a janela de abril é a mais credível, sustentada por reportagem do portal chinês Whale Lab e corroborada por fontes técnicas que apontam para a segunda quinzena do mês.
Se os benchmarks de codificação se confirmarem — especialmente a performance no SWE-bench — o V4 se tornará a escolha óbvia para equipes de engenharia que precisam de capacidade de repositório inteiro, análise multi-arquivo e geração de código complexo. A combinação de desempenho com custo radicalmente inferior é uma equação que poucos CFOs resistirão.
A janela de contexto de 1 milhão de tokens com recuperação de alta fidelidade via Engram resolve um dos maiores pontos de dor do desenvolvimento assistido por IA: a necessidade de fragmentar código em pedaços menores para caber no contexto do modelo, perdendo a visão do sistema como um todo.
Agentes de IA autônomos com memória persistente — o caso de uso central que o V4 foi projetado para habilitar — estão prestes a se tornar economicamente viáveis em uma escala sem precedentes. Um agente que lembra o que fez ontem, que mantém contexto de projetos ao longo de semanas e que custa centavos por milhão de tokens processados é uma proposta de valor transformadora para automação empresarial.
O V4 é o primeiro modelo de ponta genuinamente projetado para independência de hardware ocidental. Se funcionar bem em chips da Huawei em escala de produção, a China terá demonstrado algo que a comunidade de IA internacional considerava improvável: que é possível manter a paridade na fronteira da IA sem acesso ao silício americano. As implicações para a eficácia das sanções tecnológicas americanas como instrumento de política externa são difíceis de exagerar.
O DeepSeek V4 é, até prova em contrário, o lançamento de IA mais significativo de 2026. Não porque vai ser maior, ou mais rápido, ou mais barato do que tudo que veio antes — embora provavelmente seja tudo isso. Mas porque ataca dois problemas fundamentais que a indústria havia aprendido a conviver como se fossem naturais: a amnésia estrutural dos agentes autônomos e a dependência de um ecossistema de hardware controlado por um único país.
O fato de que o modelo ainda não chegou, depois de meses de antecipação, conta uma história em si mesmo. A DeepSeek não está lançando uma atualização. Está tentando reescrever a arquitetura de como modelos de IA funcionam — e fazer isso ao mesmo tempo em que desenvolve a infraestrutura de hardware para rodar essa arquitetura sem depender do Ocidente.
Quando o V4 finalmente aparecer — seja em abril, seja mais tarde — a pergunta não será “é melhor que o V3?”. A pergunta será: o mercado global está pronto para uma IA que lembra, que vê, que coda melhor que qualquer concorrente, e que roda em hardware que os EUA não podem bloquear?
A resposta vai importar muito além do mundo da tecnologia.
Atualizado em 28 de março de 2026. O DeepSeek V4 ainda não foi lançado publicamente. Este artigo será atualizado assim que a empresa fizer o anúncio oficial.
⚙️ n8n: o guia completo da automação com IA
Entenda como o n8n está redefinindo workflows e integração com inteligência artificial.
Um guia prático para dominar automação moderna com controle total.
🤖 Ferramentas de IA em 2026
Veja quais ferramentas realmente aumentam produtividade — e quais são apenas tendência passageira.
Uma análise estratégica para montar seu stack de IA.
🔍 Perplexity AI: vale substituir seu stack?
Descubra se o Perplexity pode assumir o papel de outras ferramentas no seu fluxo.
Comparativo direto com foco em uso real e eficiência.
Se esse artigo fez você se perguntar como o DeepSeek V4 pode mudar a forma como você programa, faz pesquisa ou pensa em automação corporativa, vale acompanhar as fontes originais e análises técnicas que vêm sendo produzidas em tempo real:






