Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


📩 Quer dominar IA, automação e as ferramentas que estão mudando o mercado? Assine a newsletter do SPTechBR e receba análises práticas toda semana.
Porque ele combina desempenho próximo aos modelos de ponta com custos significativamente menores e distribuição open source. Isso reduz barreiras de entrada, acelera a adoção corporativa e aumenta a pressão competitiva sobre todo o mercado de inteligência artificial.
Quando publicamos a primeira versão deste artigo em 30 de março de 2026, o DeepSeek V4 havia se tornado o lançamento de IA mais aguardado do ano — e o mais atrasado. Cada janela de lançamento havia passado em silêncio: o Ano Novo Chinês em fevereiro, as “Duas Sessões” parlamentares em março.
Em 24 de abril de 2026, a espera terminou.
A DeepSeek lançou simultaneamente dois modelos — V4-Pro e V4-Flash — disponíveis imediatamente via API pública e com pesos completos no Hugging Face sob licença MIT. A versão foi rotulada como “preview” pela empresa, sinalizando que o desenvolvimento continua e que capacidades adicionais — especialmente a multimodalidade nativa, que apareceu em interfaces de teste mas não foi incluída no lançamento público — devem ser incorporadas antes da versão estável.
O lançamento em preview indica que o modelo está estável o suficiente para uso em produção, mas a DeepSeek não anunciou uma data para a versão “estável”, e capacidades como modos visuais e multimodais aparecem em interfaces de teste mas não fazem parte dos modelos enviados.
O que chegou já é suficiente para mudar o cálculo de qualquer equipe que usa IA para programação, automação ou agentes.
O DeepSeek V4 não é um modelo único. É uma família de dois produtos com propostas distintas que cobrem casos de uso diferentes.
DeepSeek V4-Pro O modelo flagship. Uma arquitetura de Mistura de Especialistas com 1,6 trilhão de parâmetros totais e 49 bilhões de parâmetros ativos por forward pass, janela de contexto de 1 milhão de tokens e licença MIT. Projetado para workflows de raciocínio complexo, codificação avançada e agentes autônomos que precisam de performance próxima à fronteira com custo muito menor.
DeepSeek V4-Flash A variante otimizada para latência e throughput. Mesma janela de contexto de 1 milhão de tokens, arquitetura mais leve com 284 bilhões de parâmetros e 13 bilhões ativos, custo ainda menor do que o V4-Pro. Posicionada para RAG, automações de alto volume e pipelines onde velocidade e custo importam mais do que performance absoluta de raciocínio.
Ambos os modelos são liberados sob licença MIT — uso comercial livre, pesos completos acessíveis no Hugging Face. O modelo de abertura da DeepSeek permanece consistente e é parte central da estratégia de adoção global da empresa.
O lançamento do DeepSeek V4 não surgiu do nada. Ele faz parte de uma estratégia mais ampla da China para reduzir a dependência tecnológica de empresas americanas e construir um ecossistema próprio de inteligência artificial. Esse movimento já vinha sendo observado em outras iniciativas do país e ajuda a explicar por que a disputa pela liderança em IA deixou de ser apenas uma questão tecnológica para se tornar também uma questão econômica e geopolítica.
O Módulo Engram — a inovação central que descrevemos em detalhes em março — chegou no V4 como prometido.
Para quem ainda não está familiarizado com o problema que ele resolve: todos os modelos de linguagem baseados na arquitetura Transformer funcionam com uma “janela de contexto” — uma quantidade limitada de informação que o modelo consegue processar simultaneamente. Quando a sessão termina ou a janela enche, tudo é esquecido.
Para agentes de IA autônomos — sistemas que precisam executar tarefas ao longo de horas, dias ou semanas sem perder o fio condutor — essa limitação é estruturalmente fatal. Um agente que esquece o que fez ontem não é um agente; é uma ferramenta de sessão única.
O Engram ataca esse problema com o que os pesquisadores chamam de “Conditional Memory via Scalable Lookup” — memória condicional por busca escalável. Em vez de processar toda informação com o mesmo peso computacional, o sistema separa conhecimento estático de raciocínio dinâmico — permitindo recuperação eficiente de fragmentos específicos de contexto sem processar tudo do zero.
O resultado prático em produção: decodificação de inferência 300% mais rápida em comparação com o V3 e manutenção de altas taxas de recuperação mesmo em documentos com mais de um milhão de tokens — o equivalente a aproximadamente seis romances ou o código-fonte completo de um projeto de software de tamanho médio.
Para empresas que estavam esperando agentes de IA para gerenciar processos de semanas sem “esquecer” etapas concluídas, o V4 com Engram é o primeiro modelo que entrega essa capacidade em escala com custo viável.
A busca por modelos capazes de processar volumes cada vez maiores de informação está diretamente ligada a uma ambição muito maior da indústria: criar sistemas que consigam compreender contexto, raciocinar e executar tarefas complexas de forma cada vez mais próxima da inteligência humana. Esse debate vai muito além de benchmarks e capacidade computacional. Em outro artigo do SPTechBR, analisamos justamente o conceito de inteligência artificial geral (AGI) e por que tantos especialistas acreditam que ela pode representar a próxima grande ruptura tecnológica da computação.

O artigo de março trabalhava com projeções. Agora temos números verificados por terceiros.
Programação — onde o V4 realmente brilha:
No SWE-bench Verified — o benchmark mais relevante para engenharia de software real, que avalia a capacidade de resolver issues reais de repositórios GitHub —, o V4-Pro marcou 80,6%. No LiveCodeBench, chegou a 93,5%. No Codeforces, obteve rating 3.206, posicionando-o no top 23 entre todos os competidores humanos.
Para contextualizar: nossa projeção de março apontava para 83,7% no SWE-bench, baseada em benchmarks internos não verificados da DeepSeek. O número real de 80,6% é ligeiramente inferior — mas ainda coloca o V4-Pro entre os melhores modelos disponíveis nessa categoria, dentro de 0,2 pontos do concorrente mais próximo no SWE-bench Verified.
Raciocínio geral:
No V4-Pro-Max (modo de raciocínio máximo), o modelo marca 87,5% no MMLU-Pro e 90,1% no GPQA Diamond — benchmarks de raciocínio científico avançado — junto com 92,6% no GSM8K para matemática.
O que o V4 não lidera:
Sendo honesto sobre as limitações — porque elas importam para quem vai tomar decisões de adoção: Claude Opus 4.7 ainda vence em loops longos de agentes; GPT-5.5 ainda vence em multimodalidade. O V4 não é o melhor modelo em tudo. É o melhor modelo para codificação e raciocínio na relação performance/custo — o que para a maioria dos casos de uso profissional é o critério que mais importa.
🔹 Comparativo de performance — principais benchmarks:
| Benchmark | DeepSeek V4-Pro | V4-Pro-Max | Referência de mercado |
|---|---|---|---|
| SWE-bench Verified | 80,6% | — | Claude Opus 4.7: ~80,8% |
| LiveCodeBench | 93,5% | — | Frontier: ~90% |
| GPQA Diamond | — | 90,1% | GPT-5.5: ~91% |
| MMLU-Pro | — | 87,5% | Frontier: ~88-90% |
| Codeforces rating | 3.206 | — | Top 23 humano |
Esta é a parte que mais impacta diretamente quem está decidindo adotar o V4 — e onde a mudança em relação ao artigo de março é mais significativa.
No lançamento em 24 de abril, o V4-Pro tinha preço de tabela de US$ 1,74 por milhão de tokens de entrada e US$ 3,48 por milhão de saída. A DeepSeek imediatamente aplicou um desconto de 75% como promoção de lançamento.
Em 22 de maio de 2026, a DeepSeek tornou esse desconto permanente. O preço atual é US$ 0,435 por milhão de tokens de entrada e US$ 0,87 por milhão de saída. Para cache hits — prompts repetidos em sistema RAG ou conversas com instrução do sistema persistente — o preço cai para US$ 0,003625 por milhão de tokens.
Para colocar em perspectiva concreta:
🔹 Comparativo de custo por milhão de tokens (output):
| Modelo | Custo por 1M tokens (output) | Comparação com V4-Pro |
|---|---|---|
| DeepSeek V4-Flash | ~US$ 0,28 | Referência mais barata |
| DeepSeek V4-Pro | US$ 0,87 | — |
| GPT-5.5 | ~US$ 30+ | ~34x mais caro |
| Claude Opus 4.7 | ~US$ 15+ | ~17x mais caro |
| Gemini 3.1 Pro | ~US$ 3,00 | ~3x mais caro |
A implicação para automações em escala é direta: agentes que fazem centenas de chamadas por hora, operando ao longo de semanas, passam de economicamente inviáveis para economicamente óbvios. A diferença entre US$ 30 e US$ 0,87 por milhão de tokens é a diferença entre um projeto que não fecha a conta e um que escala sem preocupação com custo de inferência.
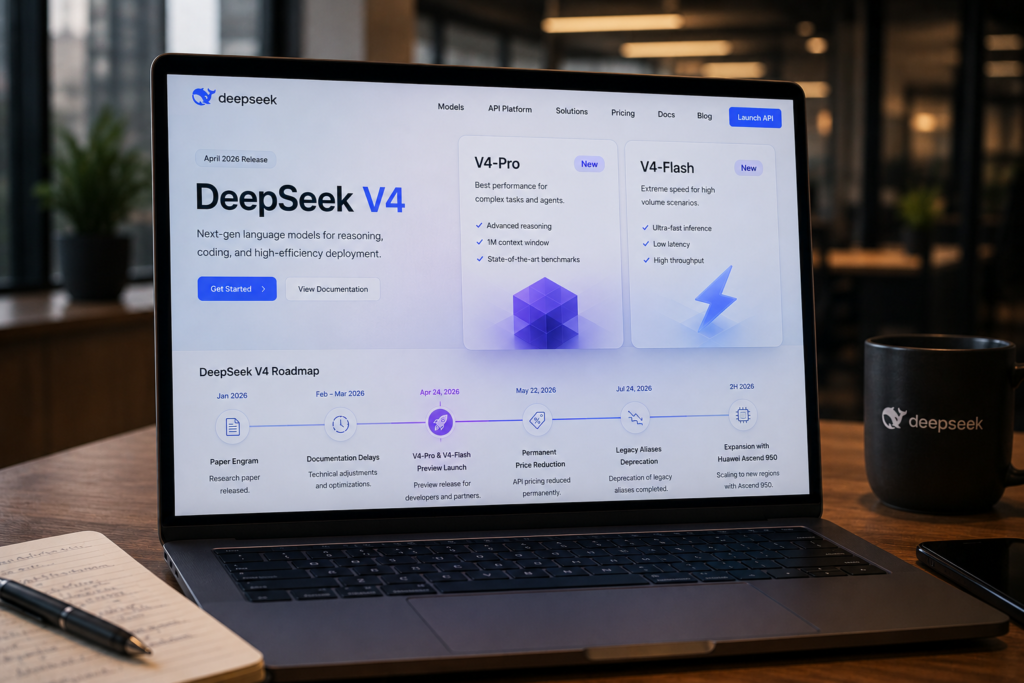
Em março, descrevemos a aposta da DeepSeek em chips domésticos chineses como um experimento ambicioso que havia causado os atrasos no lançamento. O lançamento de abril confirmou e expandiu essa narrativa.
Os atrasos que documentamos — problemas de estabilidade no treinamento com chips Ascend da Huawei, imaturidade do ecossistema de software — foram reais. A DeepSeek não desistiu. Dedicou meses de engenharia para resolver esses problemas.
O resultado: a DeepSeek nota que o preço do V4-Pro pode cair ainda mais no segundo semestre de 2026, uma vez que os chips Ascend 950 ultra-node da Huawei se tornem amplamente disponíveis. Em outras palavras, a infraestrutura de hardware doméstico chinesa está se tornando parte central da estratégia de precificação e escalabilidade da empresa — não apenas uma alternativa de emergência às sanções americanas.
Se o V4 é competitivo com os melhores modelos ocidentais e foi treinado e está sendo executado em infraestrutura que os EUA não podem bloquear, a eficácia das sanções de chips como instrumento de contenção tecnológica fica ainda mais em questão.
H2
Para equipes de desenvolvimento que estão avaliando adoção, os dados reais permitem uma recomendação mais direta do que era possível em março.
Use V4-Pro quando:
Use V4-Flash quando:
Ainda considere Claude Opus 4.7 ou GPT-5.5 quando:
Comparações entre modelos costumam gerar manchetes, mas a pergunta mais importante para empresas e profissionais continua sendo a mesma: qual ferramenta realmente faz sentido para cada necessidade? Um modelo pode liderar determinados benchmarks e ainda assim não ser a melhor escolha para um caso de uso específico. Para aprofundar essa análise, o SPTechBR publicou um comparativo completo entre ChatGPT, Claude, Gemini e DeepSeek, explorando as vantagens e limitações de cada plataforma em cenários reais de trabalho.
O caso de uso que mais muda com o V4 não é o de desenvolvedores individuais. É o de empresas que estavam esperando que agentes de IA autônomos se tornassem economicamente viáveis em escala.
Com o Engram resolvendo a limitação de memória e os preços a US$ 0,87 por milhão de tokens de saída, a equação muda fundamentalmente para operações que dependem de automação cognitiva contínua.
Um agente de análise jurídica que mantém contexto de processos ao longo de semanas. Um sistema de atendimento que lembra do histórico completo de cada cliente sem reprocessar tudo. Uma automação de código que opera repositórios inteiros sem perder o contexto de decisões arquiteturais anteriores.
Essas eram promessas. Com o V4, começam a ser projetos com planilha de viabilidade econômica.
A estratégia adotada pelo DeepSeek também ajuda a entender uma mudança importante no mercado de inteligência artificial. Enquanto algumas empresas apostam em ecossistemas fechados e altamente controlados, outras defendem modelos mais acessíveis para acelerar inovação e adoção. Essa disputa não acontece apenas entre empresas, mas entre visões diferentes de como a própria infraestrutura da IA deve evoluir. O tema aparece de forma recorrente em outro conteúdo do SPTechBR, onde analisamos a estratégia do Google para construir um ecossistema completo de inteligência artificial ao redor do Gemini e de seus agentes.
Sendo honesto sobre o que o artigo de março prometia e o lançamento de abril ainda não entregou:
Multimodalidade nativa completa: o V4 foi descrito como nativamente multimodal para texto, imagem e vídeo. Os modos visuais aparecem em interfaces de teste, mas não fazem parte do lançamento público de preview. Capacidades multimodais não verificadas não fazem parte dos modelos enviados.
Versão estável: o lançamento é explicitamente rotulado como preview. A DeepSeek não forneceu cronograma para a finalização.
Legado dos aliases: deepseek-chat e deepseek-reasoner estão marcados para deprecação em 24 de julho de 2026. Até essa data, os aliases roteiam para V4-Flash de forma transparente. Quem usa a API da DeepSeek em produção precisa atualizar os model IDs antes dessa data.

Desde o lançamento em abril, a família V4 cresceu para incluir múltiplas variantes: o modelo base de 1 trilhão de parâmetros, V4-Pro, V4-Flash, e modos de raciocínio estendido (High e Max) para cada variante.
O posicionamento no mercado ficou mais claro após semanas de uso em produção pela comunidade:
O que não mudou desde março: o DeepSeek continua sendo a empresa que força uma reavaliação de preços em toda a indústria. Cada lançamento da DeepSeek pressiona concorrentes a justificar suas estruturas de custo de uma forma diferente das de 18 meses atrás.
Talvez a contribuição mais relevante do DeepSeek não esteja apenas no avanço técnico, mas no efeito econômico provocado por modelos cada vez mais eficientes e baratos. Quando o custo da inteligência artificial diminui, novas aplicações se tornam viáveis e barreiras de entrada começam a desaparecer. Essa perspectiva é central para compreender a transformação atual da indústria. Em outro artigo do SPTechBR, mostramos por que a revolução da IA pode ser muito mais econômica do que tecnológica — e por que isso tem implicações profundas para empresas, mercados e profissionais.
Em março, escrevemos: “Quando o V4 finalmente aparecer, a pergunta não será ‘é melhor que o V3?’ A pergunta será: o mercado está pronto para uma IA que lembra, que vê, que coda melhor que qualquer concorrente, e que roda em hardware que os EUA não podem bloquear?”
O V4 chegou. A resposta parcial está chegando também.
Ele lembra — o Engram funciona como prometido. Ele coda no nível da fronteira — os benchmarks confirmam. Ele roda em hardware fora do controle americano — e os preços vão cair ainda mais quando os chips Huawei Ascend 950 escalarem.
O que ainda não chegou é a multimodalidade completa — e essa continua sendo a peça que vai definir se o V4 consegue competir com Gemini e GPT-5.5 em tudo, ou se permanece como o campeão de custo-benefício em codificação e raciocínio.
Para desenvolvedores e empresas avaliando adoção: o momento de testar é agora. O preview está estável o suficiente para produção. Os preços estão permanentes. Os pesos estão abertos.
A pergunta não é mais se o V4 vale a atenção.
É o que você vai construir com ele.
O DeepSeek V4 não é apenas um modelo novo. É a confirmação de que a corrida global da IA não tem um líder único.
E que quem define o ritmo pode mudar de um lançamento para o outro.
📩 Toda semana, o SPTechBR analisa o que está realmente acontecendo com IA — sem hype e sem ignorar o que ainda não funciona.
🌐 A Guerra Fria da Inteligência Artificial → O contexto geopolítico mais amplo da corrida em que o DeepSeek V4 é o mais recente capítulo.
🔧 A Crise do Hardware → Por que chips e infraestrutura são o verdadeiro campo de batalha da IA — e o que a Huawei tem a ver com isso.
💻 Como rodar IA local em 2026 → O V4 tem pesos abertos e pode rodar localmente — este guia mostra como.
🤖 O fim dos copilotos? Como agentes de IA estão assumindo tarefas → O caso de uso mais transformador do V4 — agentes autônomos com memória persistente.
Sim. O DeepSeek V4 foi lançado em 24 de abril de 2026 em versão preview, com dois modelos disponíveis: V4-Pro e V4-Flash. Ambos estão disponíveis via API pública e com pesos completos no Hugging Face sob licença MIT.
O V4-Pro é o modelo flagship com 1,6 trilhão de parâmetros totais e 49 bilhões ativos, otimizado para raciocínio complexo, codificação avançada e agentes autônomos. O V4-Flash tem 284 bilhões de parâmetros e 13 bilhões ativos, otimizado para latência e throughput em pipelines de alto volume. Ambos têm janela de contexto de 1 milhão de tokens.
O preço atual permanente do V4-Pro é US$ 0,435 por milhão de tokens de entrada e US$ 0,87 por milhão de saída. O V4-Flash é ainda mais barato, em torno de US$ 0,28 por milhão de tokens de saída. Para cache hits em RAG e sistemas com prompts repetidos, o V4-Pro cai para US$ 0,003625 por milhão de tokens de entrada.
Em codificação e custo-benefício, sim — o V4-Pro marca 80,6% no SWE-bench Verified, competitivo com Claude Opus 4.7, a uma fração do custo. Em loops longos de agentes, Claude Opus 4.7 ainda tem vantagem. Em multimodalidade, GPT-5.5 ainda lidera. O V4 não é o melhor em tudo, mas é o melhor na relação performance/custo para a maioria dos casos de uso de programação e raciocínio.
O suporte a imagem e vídeo aparece em interfaces de teste, mas não faz parte do lançamento público de preview de abril de 2026. A DeepSeek não confirmou data para inclusão de capacidades multimodais na versão pública.
Sim. Os pesos completos do V4-Pro e V4-Flash estão disponíveis no Hugging Face sob licença MIT. Devido à arquitetura MoE e quantização (INT8/INT4), é tecnicamente possível rodar o modelo em hardware de consumo de alta especificação. O guia completo sobre como rodar IA local está disponível no SPTechBR.






