Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


📩 Receba análises práticas sobre IA, ferramentas e produtividade — toda semana, direto no seu e-mail.
Para rodar IA local, você precisa de pelo menos 16 GB de RAM, SSD e um computador dos últimos cinco anos. As ferramentas mais acessíveis são o Ollama (linha de comando, instalação em minutos) e o LM Studio (interface gráfica, ideal para iniciantes). Você baixa um modelo open source como Llama 3 ou Mistral e executa tudo diretamente no seu computador, sem enviar dados para a internet.
Depois de usar ferramentas como ChatGPT e Claude no dia a dia, um ponto começou a ficar claro: nem tudo deveria ser enviado para a nuvem.
Contratos, análises estratégicas, materiais com dados de clientes — conteúdos que você até gostaria de processar com IA, mas que exigem mais controle sobre onde esses dados estão sendo usados.
Foi a partir desse tipo de situação que rodar IA local deixou de ser apenas curiosidade técnica e passou a fazer sentido como alternativa prática.
E o que fica evidente quando você começa a explorar esse caminho é que a realidade é diferente do que muitos tutoriais fazem parecer. Rodar IA local em 2026 é, sim, viável — e mais acessível do que nunca. Mas a experiência ainda está longe de replicar o que você encontra em ferramentas como ChatGPT ou Claude.
Na prática, isso significa que entender os limites desde o início evita frustração — e ajuda a usar a tecnologia do jeito certo.
Este guia foi construído justamente com esse objetivo: mostrar o que realmente importa. Os requisitos de hardware com números concretos, as ferramentas que fazem sentido dependendo do seu perfil, quais modelos valem a pena — e, principalmente, o que funciona de verdade no uso diário.
Para entender por que rodar IA local faz parte de um movimento maior — de profissionais construindo sua própria infraestrutura de IA — vale complementar com este guia sobre como criar produtos e operações completas com IA em 2026 →
Muitos tutoriais sobre IA local erram nos dois extremos: ou superestimam o hardware necessário (“você precisa de uma GPU top de linha”) ou subestimam as limitações (“qualquer computador funciona”). A realidade é mais nuançada — e mais honesta do que qualquer um dos dois extremos.
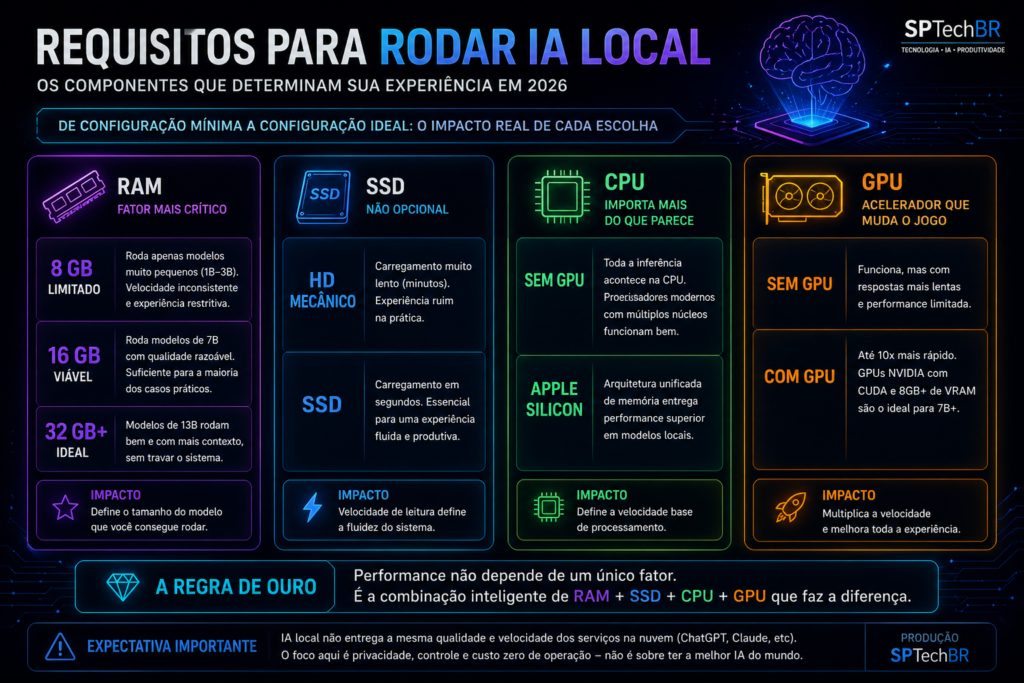
Na primeira vez que tentei rodar IA local com 8 GB de RAM, a experiência foi frustrante. O modelo carregava parcialmente, as respostas demoravam mais do que o esperado, e o computador ficava travado para qualquer outra tarefa simultânea. Vale entender o que cada faixa entrega na prática:
SSD — não opcional: Se você ainda tem HD mecânico, esqueça IA local por enquanto. O carregamento dos modelos exige leitura rápida de arquivos grandes — um modelo de 7B tem entre 4 e 8 GB de peso. Em SSD, o carregamento leva segundos. Em HD, pode levar minutos — e a experiência simplesmente não vale a pena.
CPU — importa mais do que parece: Sem GPU, toda a inferência acontece na CPU. Processadores modernos com múltiplos núcleos funcionam bem — especialmente os chips M1/M2/M3 da Apple, que têm arquitetura unificada de memória. Essa característica específica faz uma diferença enorme que vou detalhar mais adiante.
GPU — o acelerador que muda o jogo: Com GPU, a velocidade de resposta pode melhorar de 5x a 10x. Placas NVIDIA com suporte a CUDA são as mais compatíveis com as ferramentas atuais. GPUs com 8 GB de VRAM ou mais já permitem rodar modelos de 7B inteiramente na GPU — o que transforma a experiência.
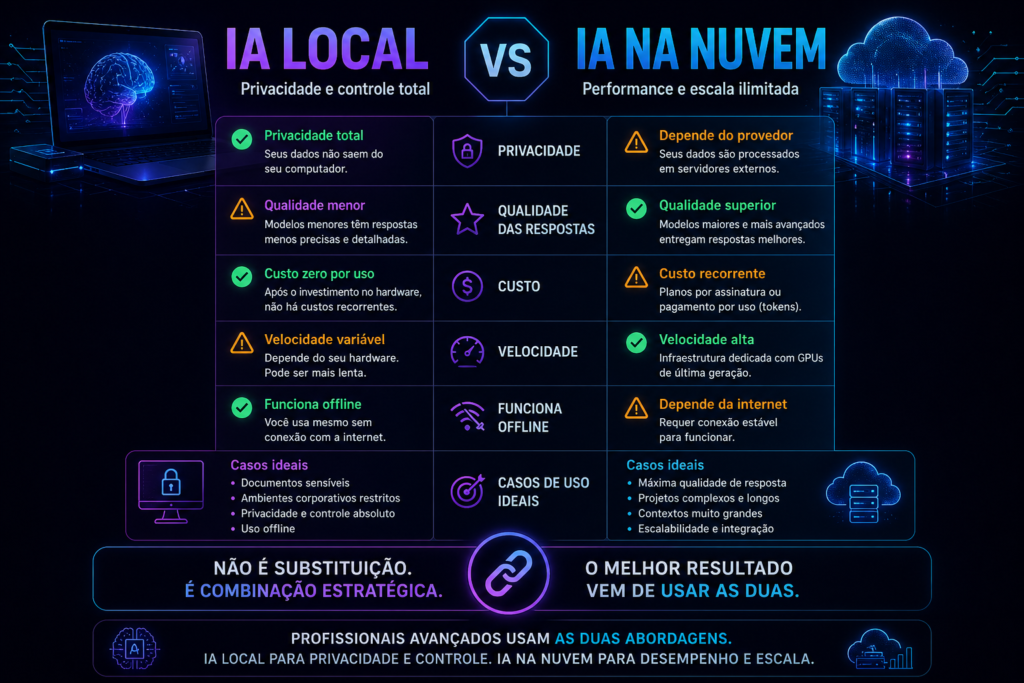
O ponto mais importante antes de começar: rodar IA local não é a mesma experiência que usar ChatGPT ou Claude.
Esses serviços rodam em clusters de centenas de GPUs de última geração. Você está rodando em um computador pessoal. A qualidade das respostas vai ser diferente — e a velocidade também. Isso não é um defeito das ferramentas — é física.
Rodar IA local é sobre privacidade, controle e custo zero de operação — não sobre ter a melhor IA disponível. Essa distinção é o que determina se faz sentido para o seu caso.
Antes de instalar qualquer ferramenta, vale entender o que está acontecendo por baixo. Não porque você precisa saber isso para usar — mas porque entender o processo ajuda a tomar decisões melhores sobre modelos e configurações depois.
mento offline. E performance limitada pelo seu hardware — o que é uma troca consciente, não um defeito.
Quando você usa ferramentas como ChatGPT ou Claude, o fluxo é relativamente simples: você digita uma mensagem, ela é enviada pela internet para um servidor externo, o processamento acontece em infraestrutura de alta performance — e a resposta retorna em segundos.
Na maioria dos casos, isso funciona perfeitamente bem. Mas existe uma implicação importante: seus dados passam por sistemas externos durante esse processo.
É justamente esse ponto que explica o crescimento recente da chamada IA offline — como exploramos neste artigo sobre por que rodar modelos de inteligência artificial no próprio computador virou uma tendência global → https://sptechbr.com/ia-offline/
Com IA local, a lógica muda completamente. Tudo acontece dentro da sua própria máquina:
Na prática, isso traz três mudanças claras: mais controle sobre dados, independência de conexão com a internet e eliminação de custo por uso.
Em contrapartida, a performance passa a depender diretamente do seu hardware — o que transforma essa escolha menos em uma questão técnica e mais em uma decisão consciente sobre controle versus conveniência.
Você vai encontrar modelos descritos como “7B”, “13B”, “70B”. Esses números indicam a quantidade de parâmetros do modelo, e são o principal fator que determina tanto a qualidade das respostas quanto a demanda de hardware.
Em termos práticos:
A tentação é sempre escolher o maior. Resista a ela — pelo menos no começo.
Existem algumas ferramentas que simplificaram radicalmente o processo. O que era um processo técnico complexo há dois anos agora é algo que qualquer pessoa consegue fazer. A curva de entrada diminuiu muito — e continua diminuindo.
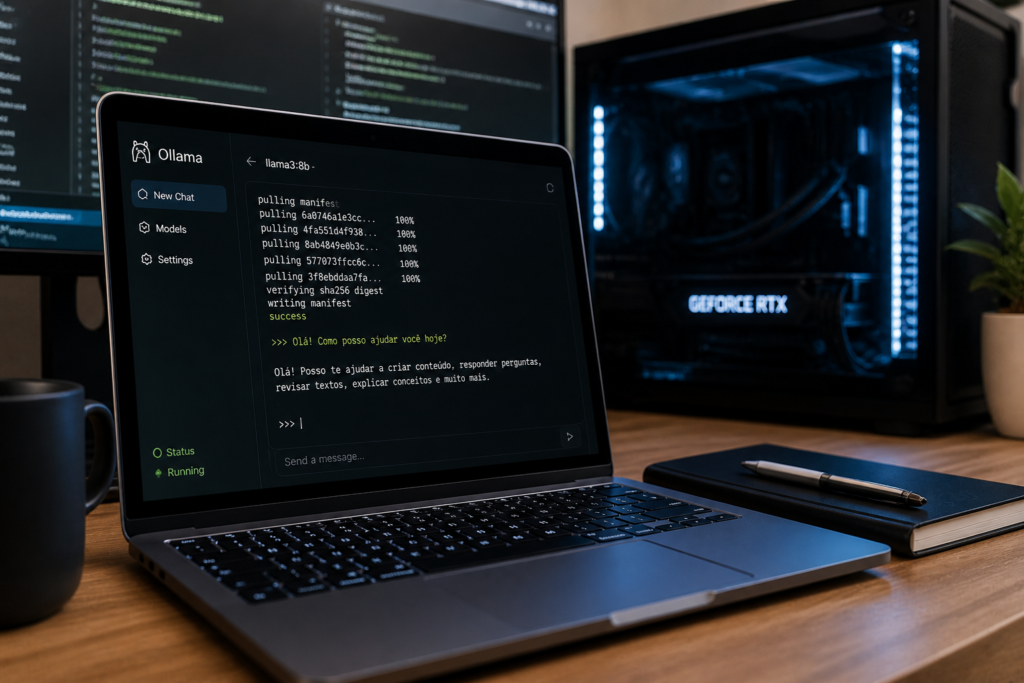
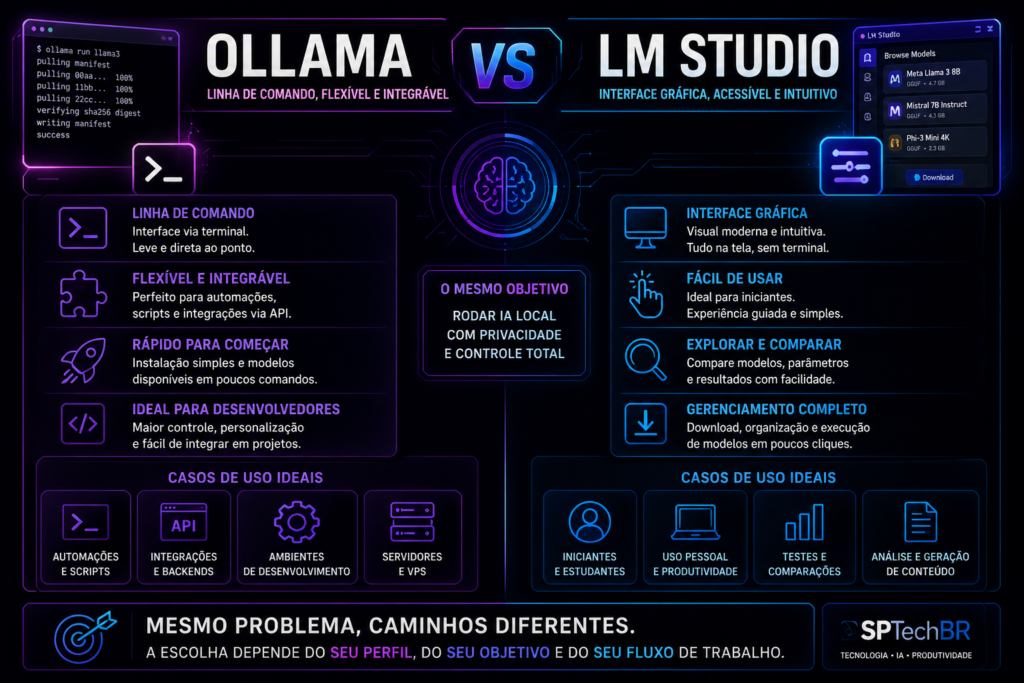
O Ollama virou o padrão para quem quer começar rapidamente e depois integrar IA local com outras ferramentas.
A instalação é simples: você baixa o instalador para o seu sistema operacional, e em minutos o Ollama está rodando. Para baixar e iniciar um modelo, o comando é tão direto quanto:
ollama run llama3Esse comando baixa o modelo Llama 3 (cerca de 4 GB para a versão 8B) e abre imediatamente uma interface de chat no terminal. Do download à primeira resposta: menos de cinco minutos em uma conexão razoável.
O que torna o Ollama especialmente valioso vai além do uso direto. Ele expõe uma API local que outras ferramentas podem usar — o que significa que você pode integrar IA local a fluxos de automação, conectando com Make, n8n ou qualquer ferramenta que aceite chamadas de API. Isso é o ponto de partida para quem quer usar IA local não apenas como assistente pessoal, mas como componente de sistemas automatizados mais amplos — como os workflows com IA que mostramos em detalhes →.
Vantagens reais:
Limitação que vale mencionar:
Se a ideia de terminal gera desconforto, o LM Studio é a alternativa certa. Ele oferece uma interface gráfica completa para baixar, gerenciar e interagir com modelos locais — com uma experiência visual que lembra, em alguns aspectos, a interface do ChatGPT.
Com o LM Studio, você navega por um catálogo de modelos disponíveis, baixa com um clique, e começa a conversar. Mais do que isso: você consegue comparar facilmente o desempenho de diferentes modelos no seu hardware específico — o que é valioso especialmente no começo, quando você ainda está descobrindo o que funciona melhor para o seu caso.
Vantagens reais:
Limitação:
H3
GPT4All — focado em simplicidade máxima. Interface minimalista, instalação em um clique, funciona offline desde o primeiro uso. Boa escolha se você quer testar IA local com o menor atrito possível antes de decidir se vale investir tempo em ferramentas mais completas.
Jan.ai — aplicativo de desktop completo com interface clean. Boa escolha para uso diário como assistente pessoal, com integração com APIs externas quando necessário.
Cursor + IA local — para desenvolvedores, o editor Cursor suporta integração com modelos locais via Ollama. Assistência de código com IA sem enviar o código para servidores externos — especialmente relevante para código proprietário. Se você já usa ferramentas de IA para programação →, vale explorar essa combinação.
Essa é a parte onde mais gente se perde. E entendo — o ecossistema de modelos open source cresceu muito rápido, e a quantidade de opções pode parecer paralisante no começo.
Mas existe uma lógica simples que resolve essa dificuldade.
Llama 3 (Meta) — disponível em 8B e 70B parâmetros. O 8B é o ponto de partida mais recomendado para uso geral: boa qualidade de resposta para escrita, análise e geração de texto, com requisitos de hardware acessíveis. O modelo mais usado na comunidade de IA local por uma razão simples — funciona bem na maioria dos casos.
Mistral 7B — surpreendentemente capaz para o tamanho, com excelente performance em seguir instruções e manter coerência. É minha primeira recomendação para quem tem 16 GB de RAM e quer uma experiência fluida. Mais leve e rápido do que o Llama 3 8B, com qualidade comparável em muitas tarefas.
Phi-3 (Microsoft) — uma família de modelos pequenos que quebra a expectativa de que modelos menores são necessariamente piores. O Phi-3 Mini (3.8B) entrega resultados impressionantes para seu tamanho. Ideal para hardware mais limitado — e surpreende positivamente.
Gemma (Google) — modelos open source com qualidade consistente. O Gemma 2 em 9B é uma boa opção para quem quer experimentar uma arquitetura diferente.
CodeLlama — variante do Llama treinada especificamente para código. Se o seu caso de uso principal é assistência de programação, essa é a escolha mais adequada.
| Seu hardware | Modelo recomendado | Por quê |
|---|---|---|
| 16 GB RAM, sem GPU | Mistral 7B ou Phi-3 | Leves e eficientes, boa qualidade |
| 16 GB RAM + GPU 8 GB | Llama 3 8B na GPU | Velocidade muito melhor |
| 32 GB RAM | Llama 3 13B ou Mistral 12B | Qualidade notavelmente superior |
| Mac com Apple Silicon | Qualquer modelo até 13B | Arquitetura unificada favorece IA local |
Não existe modelo universalmente certo. Existe o modelo mais adequado para o seu hardware e o seu caso de uso específico.
Chega de teoria. Aqui está o que aconteceu em testes reais com configurações representativas para a maioria dos profissionais que estão explorando IA local em 2026.
Configuração 1: Notebook com 16 GB RAM, sem GPU — Mistral 7B via Ollama
Esse é o cenário mais comum para quem está começando. A velocidade de resposta ficou em torno de 15 a 25 tokens por segundo — respostas curtas chegam em segundos, mas textos mais longos levam 30 segundos a um minuto.
Não é a experiência fluida do ChatGPT. Mas é funcional — e para muitos casos de uso, suficiente.
O que funcionou muito bem:
O que funcionou com limitações notáveis:
O que não funcionou bem:
Configuração 2: MacBook Pro M2, 16 GB RAM — Llama 3 8B via Ollama
Essa é onde a surpresa aparece. A arquitetura unificada de memória dos chips Apple Silicon faz uma diferença enorme. O mesmo modelo roda 3x a 4x mais rápido do que em um PC sem GPU dedicada — com respostas fluidas e latência baixa para respostas de tamanho médio.
Se você tem um Mac com chip M-series, a experiência de rodar IA local é genuinamente boa para uso diário. Não precisei de nenhuma configuração adicional — funcionou bem logo na primeira instalação.
Rodar IA local é uma ferramenta excelente como assistente pessoal privado. Mas ela não substitui modelos de ponta da nuvem para tarefas que exigem o máximo de qualidade.
Quem entende isso usa IA local onde ela é genuinamente superior — privacidade e controle — e continua usando ferramentas cloud onde a qualidade importa mais do que a privacidade. Esse modelo híbrido é o que faz mais sentido na prática para a maioria dos profissionais.
E isso conecta diretamente com o que mostramos sobre como usar ChatGPT no trabalho de forma estratégica →: as duas abordagens não competem — se complementam quando você sabe quando usar cada uma.
Este é o caso de uso onde IA local tem a vantagem mais clara e inegociável: analisar documentos que você não quer que saiam do seu computador.
Contratos, análises financeiras, documentos médicos, estratégias empresariais, código proprietário — qualquer conteúdo sensível o suficiente para que você hesite antes de colar no ChatGPT pode ser processado localmente com tranquilidade.
Na prática, você coloca o texto do documento na interface de chat e pede o que precisar — resumo, análise de pontos críticos, extração de informações específicas. A qualidade não vai ser a mesma de um modelo de ponta da nuvem, mas para análises gerais e extração de informação, funciona muito bem.
Geração de rascunhos, brainstorm de ideias, organização de notas — tudo isso funciona bem com modelos locais, especialmente quando você precisa de privacidade ou simplesmente está sem internet.
Esse tipo de uso complementa bem o que mostramos sobre Notion AI na prática →: o Notion AI é superior para quem trabalha dentro do ecossistema Notion, mas IA local é a alternativa quando você não quer que seus rascunhos passem por servidores externos.
Para desenvolvedores, rodar IA local via Ollama com CodeLlama ou outro modelo de código, integrado ao editor, permite assistência de programação sem enviar código proprietário para servidores externos.
Isso é especialmente relevante para quem trabalha com contratos que têm cláusulas de confidencialidade — algo mais comum do que parece, e uma situação onde IA local resolve um problema real.
IA local pode ser integrada como componente de fluxos maiores de automação via Ollama API. Dados sensíveis são processados localmente pela IA, enquanto as etapas não sensíveis usam ferramentas cloud.
Isso conecta diretamente com o que mostramos em workflows com IA e automação de processos completos →: a IA local é a peça para as etapas onde privacidade de dados é um requisito — não uma limitação, mas uma escolha estratégica.
Para quem quer entender como modelos de linguagem funcionam, experimentar com diferentes arquiteturas ou explorar o ecossistema de IA open source, rodar IA local é o ambiente perfeito. Controle total, custo zero por experimento, sem limite de uso.
| Critério | IA local | IA na nuvem (ChatGPT, Claude) |
|---|---|---|
| Privacidade de dados | ✅ Total — nada sai do computador | ⚠️ Dados processados em servidores externos |
| Qualidade das respostas | ⚠️ Boa (modelos menores) | ✅ Excelente (modelos de ponta) |
| Custo de operação | ✅ Zero (após setup de hardware) | ⚠️ Por uso ou assinatura mensal |
| Funcionamento offline | ✅ Sim, funciona sem internet | ❌ Requer conexão estável |
| Velocidade de resposta | ⚠️ Depende muito do hardware | ✅ Rápida e consistente |
| Contexto disponível | ⚠️ Limitado pelo hardware | ✅ Contextos maiores disponíveis |
| Atualização de conhecimento | ❌ Data de corte fixa | ✅ Modelos atualizados regularmente |
| Configuração inicial | ⚠️ Requer setup | ✅ Pronto para usar |
H3
Na prática, o futuro não é uma escolha entre IA local e IA na nuvem. É a combinação inteligente das duas.
Documentos sensíveis? IA local. Análise estratégica que exige qualidade máxima? Claude ou GPT-4. Brainstorm rápido sem preocupação com privacidade? Qualquer dos dois. Processamento automatizado de dados internos em um workflow? IA local via API do Ollama.
Quem entende quando usar cada abordagem opera com uma vantagem real sobre quem usa apenas uma das duas de forma exclusiva. Essa lógica é a mesma que governa como profissionais avançados pensam sobre automação com IA no geral →: a ferramenta certa para o contexto certo, não a ferramenta favorita para tudo.
(Schema HowTo — estruturar com plugin de Schema Markup no WordPress)
Passo 1: Verifique se seu hardware é adequado Confirme que você tem pelo menos 16 GB de RAM e SSD. Se tiver GPU NVIDIA com 8 GB de VRAM ou mais, ou um Mac com chip Apple Silicon, você vai ter uma experiência ainda melhor. Com menos do que isso, vale testar — mas ajuste a expectativa.
Passo 2: Escolha a ferramenta de acordo com o seu perfil
Passo 3: Instale a ferramenta escolhida Para Ollama: acesse ollama.ai, baixe o instalador para o seu sistema operacional e siga as instruções — são menos de cinco minutos.
Para LM Studio: acesse lmstudio.ai, baixe a versão para o seu sistema, instale e abra.
Passo 4: Escolha e baixe seu primeiro modelo Para começar, o Mistral 7B ou o Llama 3 8B são os mais recomendados — ambos oferecem bom equilíbrio entre qualidade e requisitos de hardware.
No Ollama: ollama run mistral
No LM Studio: busque “Mistral 7B” no catálogo interno e clique em Download.
Passo 5: Teste com uma tarefa real do seu trabalho Não teste com uma pergunta aleatória. Teste com algo real: cole um documento que você precisaria analisar, peça um resumo, peça para identificar os pontos principais. O teste real é o que define se a ferramenta vai ou não entrar na sua rotina — e é onde você vai descobrir o que o seu hardware consegue entregar na prática.
Passo 6: Configure a integração se quiser ir além Se você usa Ollama e quer integrar com workflows de automação via Make ou n8n, a API local do Ollama expõe um endpoint em localhost:11434 que pode ser chamado por qualquer ferramenta que aceite requisições HTTP. Esse é o caminho para transformar IA local em componente de um sistema maior.
Há dois anos, rodar IA local era principalmente território de entusiastas e desenvolvedores avançados. Em 2026, o perfil de quem usa IA local mudou — e continua mudando rápido.
Três forças estão acelerando essa mudança:
Regulamentação de privacidade: empresas em setores como saúde, direito e finanças estão encontrando IA local como resposta para compliance com LGPD e regulações similares, que limitam o compartilhamento de dados com serviços externos. Esse driver sozinho está criando demanda real em segmentos que antes não cogitavam IA local.
Custo de operação: para casos de uso de alto volume — processar milhares de documentos, por exemplo — o custo de API de modelos cloud se torna significativo. IA local, após o investimento inicial em hardware, tem custo marginal zero. A matemática eventualmente fecha.
Modelos open source ficando melhores: a cada trimestre, os modelos disponíveis para rodar localmente ficam mais capazes. A diferença de qualidade entre modelos open source e modelos proprietários de ponta está diminuindo — especialmente para casos de uso específicos e bem definidos.
O movimento de IA local faz parte de algo mais amplo: a democratização da infraestrutura de IA. Para profissionais que estão construindo uma operação baseada em IA — seja como freelancer, consultor ou em uma equipe pequena — rodar IA local é uma peça da infraestrutura.
Não a única peça. Mas uma importante para os casos onde privacidade e controle importam mais do que conveniência. Isso conecta diretamente com o que analisamos sobre como profissionais estão operando como empresas inteiras usando IA como infraestrutura →: a IA local é a camada de dados sensíveis dessa infraestrutura — discreta, mas estrategicamente relevante.
Vale a pena se você:
Pode não valer se você:
O veredicto direto:
Rodar IA local não substitui a nuvem. Complementa. E esse complemento tem valor real para quem entende quando usá-lo.
Para quem lida com informações sensíveis, tem hardware razoável e quer privacidade sem abrir mão de assistência inteligente no trabalho, vale absolutamente a pena. O melhor cenário — e o mais comum entre quem usa IA de forma avançada — é ter as duas opções disponíveis e saber qual usar em cada contexto.
📩 Quer sair do uso básico de IA e entender como aplicar de forma estratégica no trabalho e na sua operação? Toda semana, o SPTechBR publica análises diretas, sem hype, sobre o que realmente funciona.
🚀 Claude + Canva: como criar carrosséis profissionais com IA (guia completo 2026)
Aprenda como usar IA na prática para criar conteúdos visuais de alto nível — do roteiro ao design final — mesmo sem experiência avançada em design.
📊 O crescimento dos tutoriais: por que esse formato domina a internet e o que isso muda para quem aprende e trabalha
Entenda por que o modelo “aprenda fazendo” se tornou dominante — e como isso está moldando a forma como profissionais evoluem e se destacam.
🧠 Mentalidade AI-first: o que é, como funciona e por que está redefinindo as empresas
Mais do que usar ferramentas, é sobre mudar a forma de pensar. Veja como a lógica AI-first está impactando decisões, processos e vantagem competitiva.
(Schema FAQPage — ativar no plugin de Schema Markup)
O que é IA local e como ela funciona? IA local é a execução de modelos de linguagem diretamente no seu computador, sem depender de servidores externos. Você baixa um modelo (como Llama 3 ou Mistral), uma ferramenta como Ollama ou LM Studio carrega o modelo na memória e o processamento acontece inteiramente no seu hardware — sem nenhum dado sair da sua máquina.
Qual computador preciso para rodar IA local? O mínimo prático é 16 GB de RAM e SSD. GPU ajuda significativamente na velocidade, mas não é obrigatória. Macs com chip Apple Silicon (M1/M2/M3) têm desempenho surpreendentemente bom para IA local, graças à arquitetura unificada de memória.
Ollama ou LM Studio — qual usar para começar? Ollama é ideal para quem tem familiaridade com terminal e quer integrar IA local com outras ferramentas via API. LM Studio é melhor para quem prefere interface gráfica e quer experimentar diferentes modelos sem linha de comando. Para o primeiro contato sem complicação: LM Studio. Para integrar com automações depois: Ollama.
Qual modelo open source é melhor para rodar localmente? Para hardware com 16 GB de RAM, Mistral 7B é a recomendação mais equilibrada — leve, rápido e com qualidade surpreendentemente boa. Llama 3 8B é excelente para uso geral. Para foco em código, CodeLlama. Para hardware mais limitado, Phi-3 Mini (3.8B) entrega resultados impressionantes para o tamanho.
IA local é melhor que ChatGPT? Não em qualidade de resposta — os modelos de ponta da nuvem ainda são superiores. IA local é melhor em privacidade (nenhum dado sai do computador), custo (zero por uso após setup) e disponibilidade offline. São propostas diferentes para necessidades diferentes — e funcionam melhor quando usadas em conjunto.
Dá para rodar IA local no celular? Sim, com modelos muito pequenos (1B a 3B parâmetros) em dispositivos de alta performance. A experiência é limitada. Para uso prático no dia a dia, computadores ainda são a plataforma mais adequada — especialmente com 16 GB de RAM ou mais.
Vale a pena rodar IA local em 2026? Depende do caso de uso. Vale a pena se você lida com documentos sensíveis, quer eliminar custo de API em uso de alto volume, precisa de IA offline ou tem um Mac com Apple Silicon. Pode não valer se você precisa da melhor qualidade possível ou tem hardware limitado. Os resultados variam significativamente com o hardware disponível.
Como integrar IA local com ferramentas de automação? O Ollama expõe uma API local em localhost:11434 que pode ser chamada por ferramentas como Make, n8n ou qualquer sistema que aceite requisições HTTP. Isso permite usar IA local como componente de workflows automatizados — especialmente útil para processar dados sensíveis que não devem sair da sua infraestrutura.
Rodar IA local com Ollama/LM Studio: 16GB RAM mínimo, modelos Mistral/Llama; privacidade total, integra API.






